头文件
本节阅读量:头文件及其用途
随着程序越来越复杂(使用更多的文件),不同cpp文件中会需要大量重复的前向声明。如果能将所有的前向声明放在一个地方,在需要时导入,会方便很多。
C++代码文件(扩展名为.cpp)并不是C++程序中唯一常见的文件类型。另一种类型的文件称为头文件。头文件通常使用.h扩展名,偶尔也会使用.hpp扩展名或没有扩展名。头文件的主要目的是将声明传播到代码(.cpp)文件中。
关键点
头文件允许将声明集中放在一起,在需要的地方导入。这可以省去多文件程序中大量冗余且单调的工作。
使用标准库头文件
考虑以下程序:
|
|
该程序使用std::cout将“Hello,world!”打印到控制台。然而,该程序从未提供std::cout的定义或声明,那么编译器如何知道什么是std::cout?
原因是std::cout已经在”iostream”头文件中进行了前向声明。当使用#include时,预处理器会将所有内容(包括std::cout的前向声明)从名为”iostream”的文件复制到#include所在的位置。
想一下如果iostream头文件不存在会怎样?无论在哪里使用std::cout,都必须手动将与std::cout相关的声明复制到使用它的地方。这将需要大量关于std::cout的知识,且是一项繁重的工作。更糟糕的是,如果添加或更改了对应的函数或变量原型,就必须手动更新所有的前向声明。
只使用#include要容易得多!
关键点
当#include引用一个文件时,所引用文件的内容将替换到#include所在的位置。这提供了一种从另一个文件中拉入声明的便捷方法。
使用头文件传播前向声明
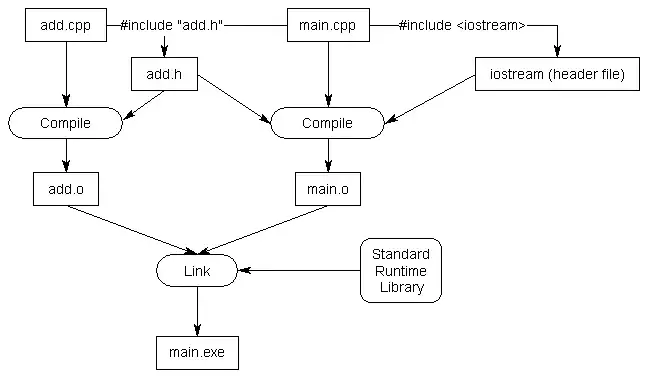
现在,回到上一课中讨论的示例。有两个文件,add.cpp和main.cpp,如下所示:
add.cpp:
|
|
main.cpp:
|
|
(如果从头开始重新创建此示例,请不要忘记将add.cpp添加到项目中,以便进行编译)。
在本例中,我们使用了前向声明,以便编译器在编译main.cpp时知道add这个标识符是什么。如前所述,为每个位于其他文件中的函数手动添加前向声明是重复且冗余的。
编写一个头文件可以减轻这个负担。编写头文件非常容易,因为头文件仅由两部分组成:
- 头文件保护,下一节中讨论。
- 头文件的实际内容。包含其它文件要使用的前向声明。
将头文件添加到项目中的工作方式类似于添加源文件。
如果使用IDE,请执行相同的步骤,并选择“头文件”而不是“源文件”。头文件应作为项目一部分出现。
如果使用命令行,只需在编辑器中创建一个文件,该文件与源(.cpp)文件位于同一目录。与源文件不同,头文件不应添加到编译命令中(它们被#include语句隐式包含并编译为源文件的一部分)。
头文件通常与代码文件配对,头文件为相应的代码文件提供前向声明。由于头文件将包含add.cpp中定义的函数的前向声明,因此新建头文件add.h。
这是对应的头文件:
add.h:
|
|
为了在main.cpp中使用此头文件,需#include引用它(使用引号,而不是尖括号)。
main.cpp:
|
|
add.cpp:
|
|
当预处理器处理#include “add.h” 时,会在该点将add.h的内容复制到当前文件中。因为add.h包含函数add() 的前向声明,所以该前向声明将被复制到main.cpp。最终结果是一个程序,其功能与main.cpp顶部添加前向声明的程序相同。
因此,程序将正确编译和链接。
最佳实践
命名头文件时首选.h后缀(除非项目已遵循其他约定)。
这是C++头文件一个长期约定,大多数IDE仍然默认为.h。
最佳实践
如果头文件与代码文件成对出现(例如,add.h与add.cpp),则它们应具有相同的基本名称(add)。
在头文件中包含定义如何导致违反单定义规则
应避免将函数或变量定义放在头文件中。如果头文件被多个源文件使用,这样做会违反单定义规则(ODR)。
下面说明这是如何发生的:
add.h:
|
|
main.cpp:
|
|
add.cpp:
|
|
编译main.cpp时,#include “add.h” 将替换为add.h的内容,然后进行编译。因此,编译器将编译如下所示的内容:
main.cpp(预处理后):
|
|
这可以编译通过。
编译器编译add.cpp时,#include “add.h” 将替换为add.h的内容,然后进行编译。因此,编译器将编译如下:
add.cpp(预处理后):
|
|
也可以很好地编译。
最后,链接器将运行。链接器将看到函数add() 有两处定义:一个在main.cpp中,另一个在add.cpp。这违反了ODR第2部分的规定,该部分指出,“在给定的程序中,变量或普通函数只能有一个定义。”
最佳实践
不要将函数和变量定义放在头文件中。
如果随后将头文件包含在多个源(.cpp)文件中,则在头文件中定义其中之一可能会导致违反单定义规则(ODR)。
注
在以后课程中,将遇到在头文件中安全定义的其他类型(因为它们不受ODR的限制)。这包括内联函数、内联变量、类型和模板的定义。在后续介绍时会进一步讨论。
代码中.h与.cpp应该成对
在C++中,最佳实践是让代码文件#include其配对的头文件(如果存在)。在上面的示例中,add.cpp引用了add.h。
这样做可以让编译器在编译时而不是链接时捕获某些类型的错误。例如:
something.h:
|
|
something.cpp:
|
|
由于something.cpp引用了something.h,编译器会注意到函数something()的返回类型不匹配,并给出编译错误。如果something.cpp没有#include something.h,就只能等到链接器发现问题,会浪费时间。
在未来的课程中,还将看到许多示例,其中源文件需要的内容在配对的头文件中定义。在这种情况下,包含头文件是必要的。
最佳实践
源文件应#include 其成对的头文件(如果存在的话)。
不#include .cpp文件
尽管预处理器能够处理,但通常不应该#include .cpp文件。这些文件应该被添加到项目中并单独编译。
这样做有许多原因:
- 可能会导致源文件之间的命名冲突。
- 在大型项目中,很难避免违反单定义规则(ODR)的问题。
- 对这样的.cpp文件的任何更改都将导致该.cpp文件和包含它的其他.cpp文件重新编译,耗时较长。与源文件相比,头文件的更改频率较低。
- 这样做是非常规的。
最佳实践
避免#include .cpp文件。
故障排除
如果出现编译器错误,指示找不到add.h,确保文件实际命名为add.h,而不是add(无扩展名)或add.h.txt或add.hpp。此外,确保它与其余代码文件位于同一目录中。
如果提示未定义函数add的链接错误,确保项目中已包含add.cpp,以便可将函数add定义链接到程序中。
尖括号与双引号
为什么对iostream使用尖括号,而对add.h使用双引号?因为在多个目录中可能存在同名的头文件。使用尖括号和双引号的区别在于给预处理器一个线索,告诉它应该在哪里查找头文件。
当使用尖括号时,预处理器知道这不是程序员自己编写的头文件。预处理器将仅在系统目录指定的目录中搜索头文件。系统目录作为项目/IDE设置/编译器设置的一部分进行配置,通常默认包含编译器和/或操作系统附带的头文件目录。预处理器不会在项目的源代码目录中搜索这类头文件。
当使用双引号时,预处理器知道这是编写的头文件。预处理器首先在当前目录中搜索头文件。如果找不到匹配的头文件,将搜索系统目录。
规则
使用双引号来include编写的或预计在当前目录中找到的头文件。使用尖括号来引用编译器、操作系统或系统上其他地方安装的第三方库附带的头文件。
为什么iostream没有.h扩展名?
另一个常见的问题是”为什么iostream(或任何其他标准库头文件)没有.h扩展名?”答案是iostream.h与iostream是不同的头文件!这需要一个简短的历史回顾。
首次创建C++时,标准库中的所有文件都以.h后缀结尾。如果一直这样也挺好。cout和cin的原始版本在iostream.h中声明。当ANSI委员会标准化C++语言时,他们将标准库中使用的标识符移到了std命名空间中,以免与用户声明的标识符发生命名冲突。然而,这会导致问题:如果将所有标识符移到std命名空间中,那么所有使用旧的iostream.h的程序都将无法编译!
为了解决此问题,C++引入了一组没有.h扩展名的新头文件,其中的标识符都声明在std命名空间中。同时保留了原来的iostream.h,这样旧程序不需要重写,而新程序也能使用#include <iostream>。
此外,从C继承的在C++中仍有用的库都被赋予了C前缀(例如,stdlib.h变为cstdlib)。
最佳实践
使用标准库头文件时,优先使用不带.h扩展名的版本。用户定义的头文件仍应使用.h扩展名。
使用标准库时,首选std命名空间中声明的标识符。
包括其他目录的头文件
另一个常见的问题是如何包含其他目录的头文件。
一种错误的方法是在#include中使用头文件的相对路径。例如:
|
|
虽然能够编译成功(在相对目录中找到了文件),但缺点是代码中会硬编码目录结构。如果目录结构改变,代码就不再工作。
更好的方法是告诉编译器或IDE,在其他位置有一组头文件,当在当前目录中找不到时,会到那里查找。这可以在IDE的项目设置中通过设置头文件路径或搜索目录来完成。
这种方法的好处是,如果更改了目录结构,只需更改单个编译器或IDE设置,而不用修改每个代码文件。
对于Visual Studio用户
在解决方案资源管理器中右键单击项目,选择属性,然后选择VC++目录选项卡。从这里,将看到头文件目录。添加希望搜索头文件的目录。
对于GCC/G++用户
g++里可以使用-I选项,指定其它头文件目录:g++ -o main -I/source/includes main.cpp
-I后面没有空格。
对于VSCode用户
在tasks.json配置文件中,在“Args”部分添加新行:“-I/source/includes”,
头文件可以include其他头文件
头文件也会使用其它头文件中声明或定义。因此,头文件通常#include其他头文件。
当#include头文件时,将获得此头文件#include的其他头文件(以及递归#include的所有头文件等)。它们是隐式包含的,而不是显式包含。
虽然递归包含的内容可在代码中使用,但不应依赖递归包含的头文件(除非参考文档指示需要递归#include)。头文件的实现可能会随着时间的推移而变化,或者在不同系统中有所不同。因此,代码可能只能在某些系统上编译,或者现在能编译但将来不能。通过显式#include代码文件所需的所有头文件,就可以避免这种情况。
不幸的是,当代码意外依赖了另一个头文件所包含的头文件时,并没有简单的方法来检测到这一点。
最佳实践
每个文件都应显式地#include需要编译的所有头文件。不要依赖于从其他头文件传递包含的头文件。
头文件的#include顺序
如果头文件编写正确,并且#include了需要的内容,那么包含的顺序应该无关紧要。
考虑以下场景:假设头文件A需要来自头文件B的声明,但没有include它。如果在代码中头文件B在头文件A之前被包含,代码仍能编译!因为编译器在处理A时,已经获得了B的全部信息。
然而,如果首先包含头文件A,那么编译器将报错,因为A中的代码在编译器看到B的声明之前就被编译了。这样错误就会暴露出来,可以及时修复。
最佳做法
要尽量提高编译器发现缺失include的概率,建议按以下顺序排列#includes:
- 与当前cpp文件对应的h文件
- 本项目中的其它头文件
- 第三方库的头文件
- 标准库的头文件
每个分组的头文件应按字母顺序排序(除非第三方库的文档有明确指示)。
头文件最佳实践
下面是创建和使用头文件的一些建议。
- 始终使用头文件保护(将在下一课中介绍)。
- 不要在头文件中定义变量和函数(目前)。
- 为头文件提供与其关联的源文件相同的名称(例如,grades.h与grades.cpp成对出现)。
- 每个头文件都应该有一个特定的功能,并且尽可能独立。例如,将与功能A相关的声明放在A.h中,将与功能B相关的声明放在B.h中。如果只关心A,则可只包含A.h,而不获取与B相关的内容。
- 注意为代码文件中使用的功能显式包含对应的头文件。
- 头文件都应该能单独编译(应该#include需要的每个依赖项)。
- 仅#include 需要的内容(不要因为允许而include所有内容)。
- 不要#include .cpp文件。
- 在头文件中放置关于某段代码的作用或使用文档。它更可能在那里被看到。描述代码如何工作的文档应保留在源文件中。
